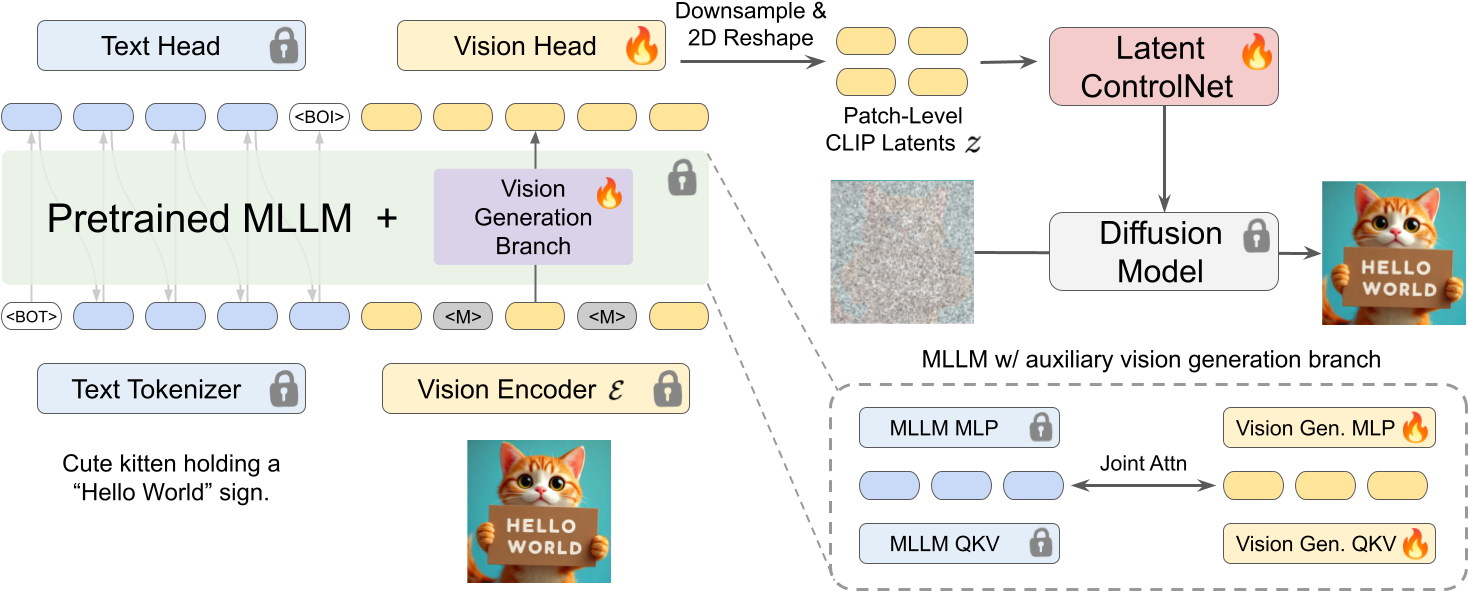
There is growing interest in integrating high-fidelity visual synthesis capabilities into large language models (LLMs) without compromising their strong reasoning capabilities. Existing methods that directly train LLMs or bridge LLMs and diffusion models usually suffer from costly training since the backbone LLMs have not seen image representations during pretraining. We present Bifrost-1, a unified framework that bridges pretrained multimodal LLMs (MLLMs) and diffusion models using patch-level CLIP image embeddings as latent variables, which are natively aligned with the MLLM's CLIP visual encoder. These patch-level image embeddings are integrated into the diffusion model with a lightweight adaptation of its ControlNet. To retain the original multimodal reasoning capabilities of MLLMs, we equip the MLLM with a visual generation branch initialized from the original MLLM parameters when predicting the patch-level image embeddings. By seamlessly integrating pretrained MLLMs and diffusion models with patch-level CLIP latents, our framework enables high-fidelity controllable image generation with significant training efficiency. Our experiments demonstrate that Bifrost-1 achieves comparable or better performance than previous methods in terms of visual fidelity and multimodal understanding, with substantially lower compute during training. We also provide comprehensive ablation studies showing the effectiveness of our design choices.
Bifrost-1 design summary. We have two main goals: (1) to preserve the multimodal understanding capability of the MLLM, while (2) efficiently teaching MLLM to generate latent tokens to guide diffusion models. As illustrated in Figure 1, Bifrost-1 achieves these goals by having a new visual generation branch initialized from the original MLLM parameters and using patch-level CLIP image embeddings as latent bridge tokens.
Learning to unmask image patch embeddings with a visual generation branch. To teach an MLLM image generation, we first encode the images using the MLLM's native visual encoder to get patch-level image embeddings and concatenate them with text tokens. Following MAR, we replace parts of the input image embeddings with a learnable mask token <M> and let the MLLM to predict the masked image embeddings. For this image embedding prediction task, we introduce a visual generation branch (Figure 1 left), whose parameters are initialized from MLLM parameters (i.e., attention QKV projections, MLP projection layers, and normalization layers) following LMFusion. Just like text head, which is a linear layer toward text embedding space, we use a simple linear layer as a vision generation head. By reusing majority of parameters from the pretrained MLLM and randomly initializing only a single linear layer as the vision head, we avoid the costly process of realigning image embeddings.
Latent ControlNet. To effectively guide diffusion models with patch-level CLIP image embeddings, we create latent ControlNet (Figure 1 top right), by modifying the original ControlNet architecture from a backbone image diffusion model (e.g., FLUX.1-dev) to take CLIP latents as input. During training, we update only the newly added input linear projection, the 2D downsampling convolution blocks, and the ControlNet for 4 MM-DiT blocks and 1 Single-DiT block, compared to the full FLUX.1-dev model which contains 19 MM-DiT blocks and 38 Single-DiT blocks in total.
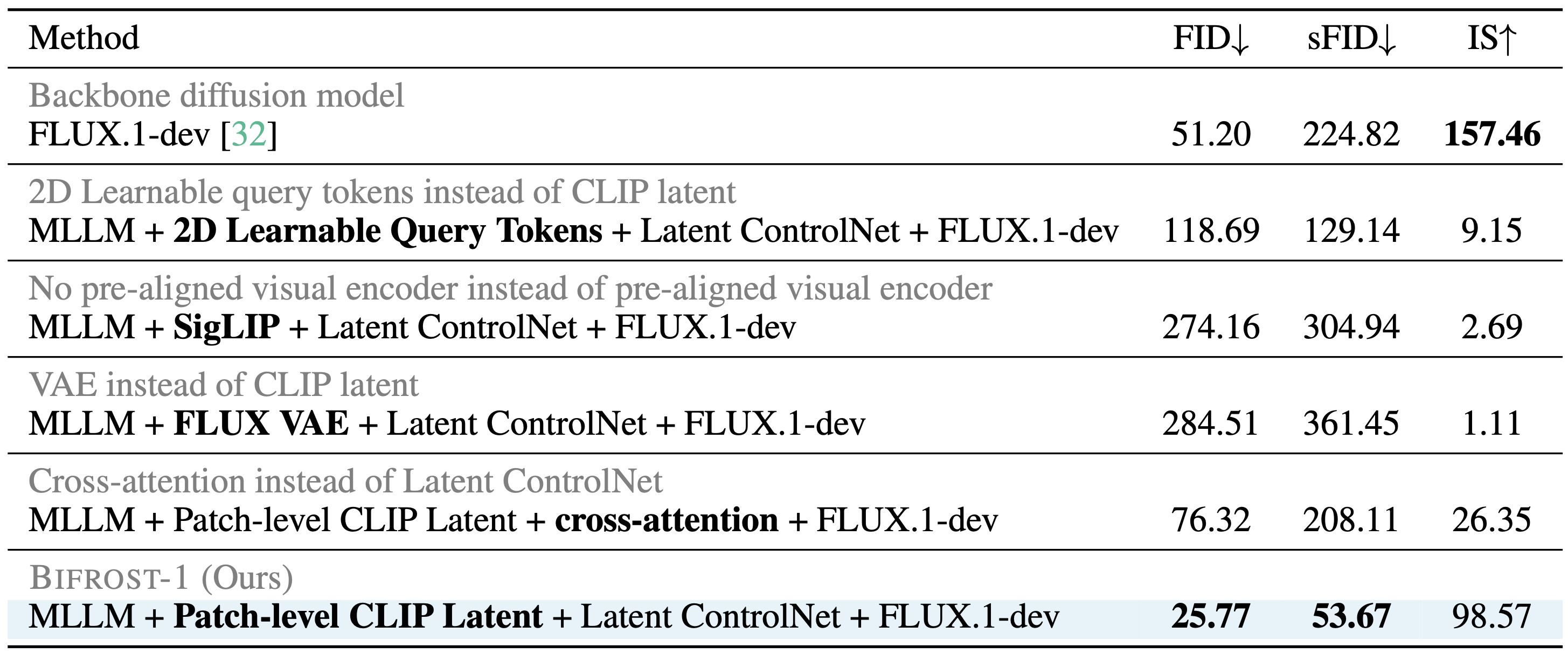
In Table 1, we compare different choices for bridging LLMs and diffusion models in terms of image generation task on ImageNet 256x256. We generate 10K images with classes randomly sampled from 1k categories and compute visual quality metrics. In all settings, the MLLM visual generation branch and the Latent \cnet{} are trained for 16 and 2 epochs, respectively.
Bifrost-1 vs. Backbone diffusion model. In the first and last rows of Table 1, we compare Bifrost-1 and its backbone diffusion model (FLUX.1-dev). We find that Bifrost-1 improves FID and sFID, while it hurts IS from the original backbone. The improvement over the baseline mainly comes from adding a few trainable ControlNet blocks to the backbone diffusion model, which enables better adaptation to the data distribution.
Patch-level CLIP latent vs. 2D learnable query tokens. MetaQuery is a recent method that bridges LLMs and diffusion models by learning a connector (24-layer transformer encoder) that projects a frozen LLM's hidden representations on a finite number of learnable query tokens, where the connector outputs guide a diffusion model via cross attentions. Inspired by this, we implement a 2D version of MetaQuery and compare it with Bifrost-1. To fairly compare methods with similar additional parameters, instead of learning a heavy connector module, we directly reshape the LLM representations of learned query tokens as inputs to the latent ControlNet. As shown in Table 1, 2D learnable query tokens hurt performance in all 4 metrics, indicating that learning to align representations between MLLM and diffusion from scratch requires much more computation than our patch-level CLIP latent.
Patch-level CLIP latents vs. VAE latents. We compare Bifrost-1 with a variant that replaces CLIP latents (that are natively aligned with MLLM) with VAE latents (that are not originally aligned with MLLMs). Specifically, we substitute the CLIP visual encoder with the FLUX VAE encoder, and replace our visual decoder (i.e., Latent ControlNet + FLUX diffusion model) with the FLUX VAE decoder. Linear projection layers are applied to align the dimensions of the VAE-encoded features with the feature dimension of the MLLM backbone. All other components of our framework and the training strategy are kept the same to ensure a fair comparison. As shown in the 3rd row of Table 1, using VAE features significantly slows down learning. Additionally, this highlights that by leveraging a pretrained diffusion model as the image renderer, Bifrost-1 effectively reduces the burden on the MLLM side to directly generate high-quality images.
MLLM's native visual encoder vs. non-aligned external visual encoder. In addition, we also compare using the latents from MLLM's native visual encoder (i.e., CLIP) with an external visual encoder (i.e., SigLIP, as used in MetaMorph). As we can see in the 4th row of Table 1, although using SigLIP achieves better image generation quality than using VAE, it is still significantly worse than using the MLLM's native visual encoder. This indicates the training efficiency of adopting MLLM's native visual encoder compared with non-aligned external visual encoders.
Diffusion model guidance strategy: Latent ControlNet vs. Cross-attention. Our method directly injects 2D image tokens generated by the MLLM into the DiT via latent ControlNet. By adding 2D ControlNet latents on top of the noisy DiT latents, our method can enforce spatial structures more explicitly and effectively. In contrast, several previous works use cross-attention to condition on image tokens. We conducted an additional experiment comparing these two conditioning strategies. For a fair comparison, we unfreeze all parameters in DiT when conditioning it via cross-attention and use 64 MLLM-generated image tokens for both methods. As shown in the 5th row of Table 1, our latent ControlNet achieves better image generation quality (FID, sFID, IS), demonstrating its superior efficiency and effectiveness.
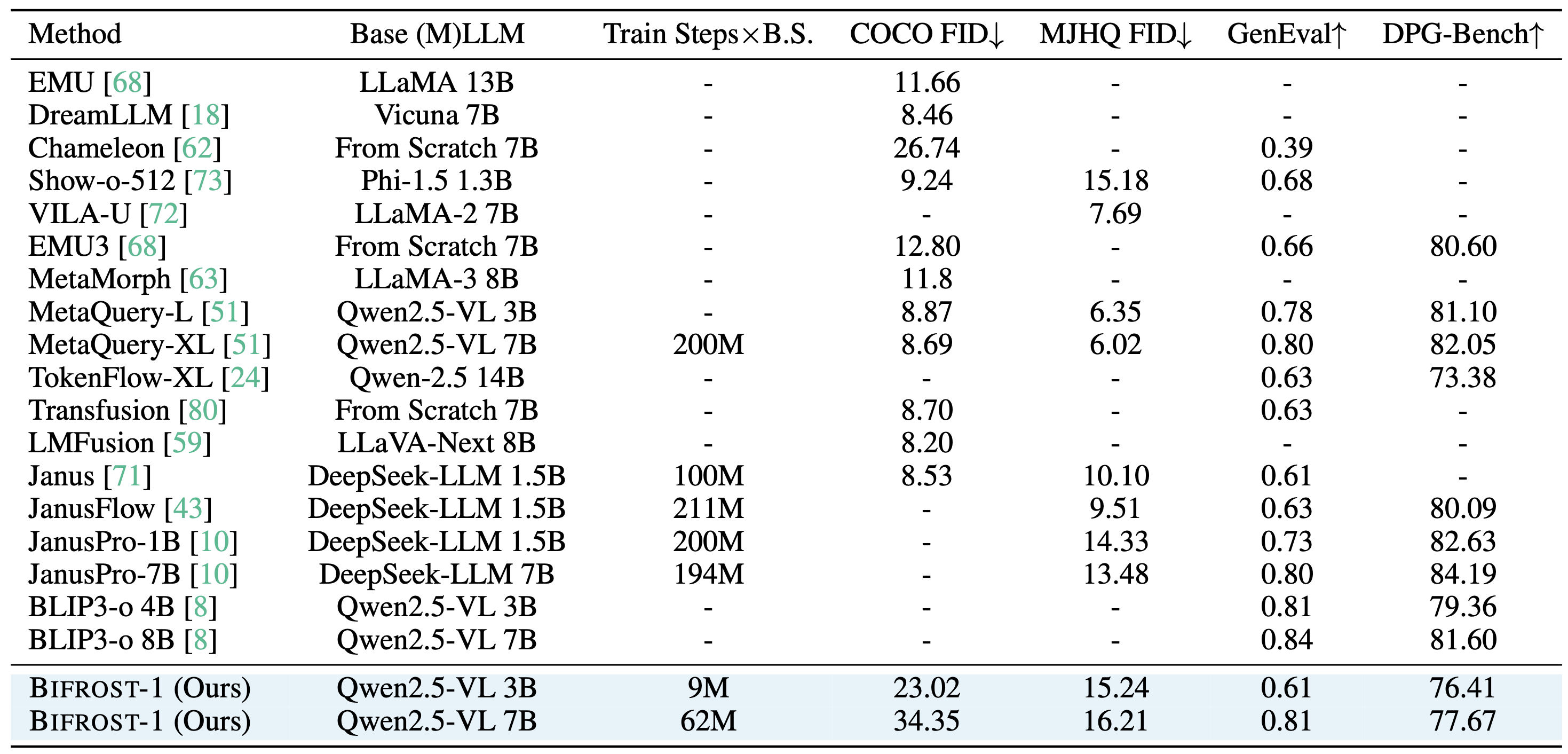
In Table 2, we compare Bifrost-1 with the recent SoTA methods (e.g., JanusPro and MetaQuery) on MJHQ30k prompts. Table 2 compares Bifrost-1 with other unified models on image generation benchmarks, including COCO and MJHQ for visual quality and GenEval and DPG-Bench for prompt following ability. Trained only with 25M image-text pairs for less than two epochs, Bifrost-1 matches the performance with models trained with much higher compute, including Janus on GenEval benchmark, and outperforms TokenFlow-XL on DPG-Bench. In addition, we would like to highlight that FID scores heavily depend on the choice of diffusion backbones. As also observed in MetaQuery, diffusion models fine-tuned on aesthetic datasets (e.g., FLUX.1-dev) typically achieve worse FID scores compared to models that have not undergone extensive aesthetic fine-tuning (e.g., SD1.5, SANA).
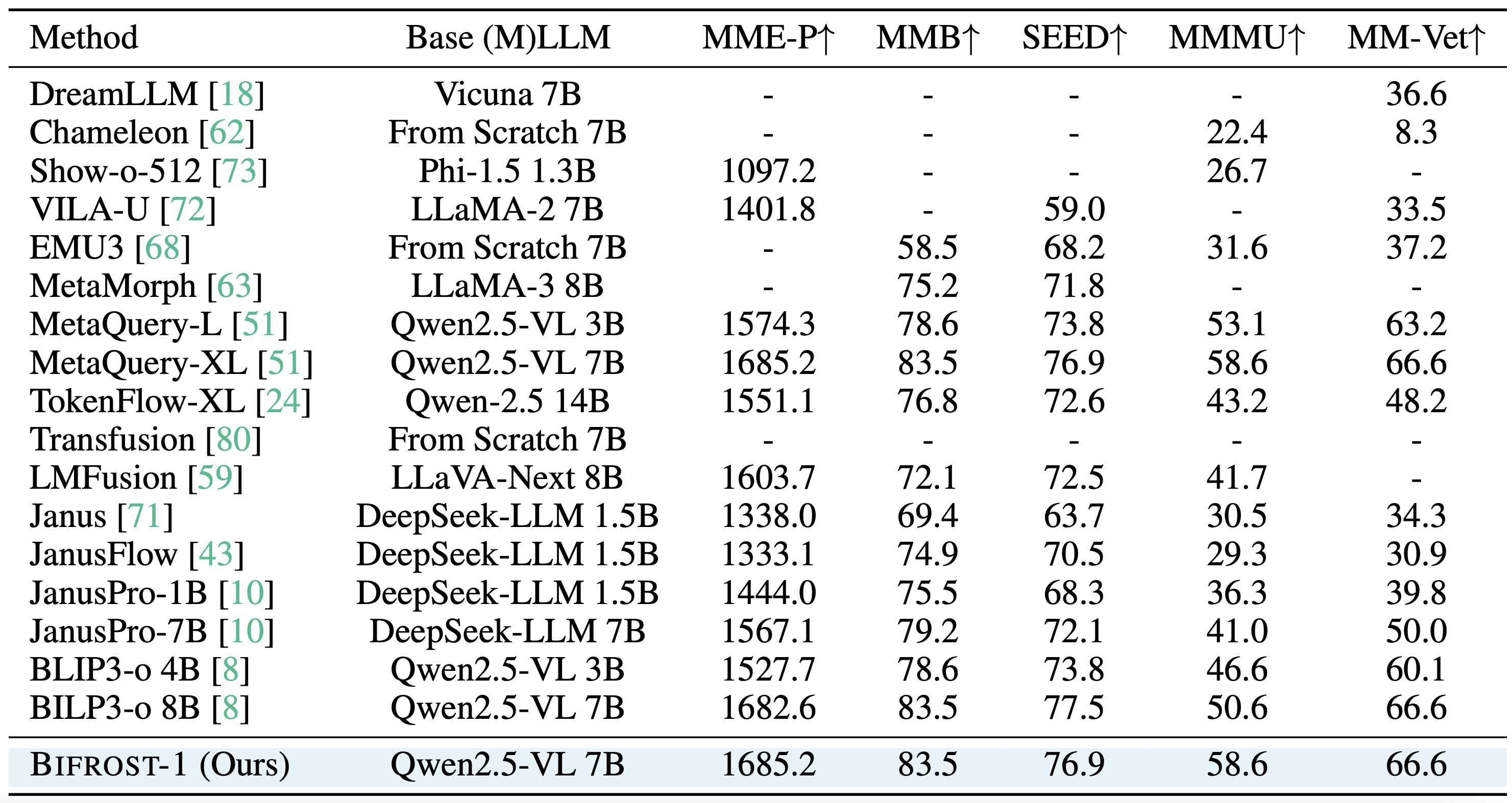
Bifrost-1 fully inherits strong visual understanding capabilities of backbone MLLM. As Bifrost-1 keeps the original parameters in the MLLM completely frozen, the trainable vision branch is agnostic to the choice of MLLM. This allows Bifrost-1 to fully inherit the visual understanding capabilities of the MLLM and easily scale to backbone MLLMs with larger sizes and stronger performance. Table 3 compares the Qwen2.5-VL 7B model with other unified models on image understanding benchmarks, including MME-P, MMB, SEED, MMMU, and MM-Vet. Baseline models such as JanusPro and MetaMorph fully fine-tune the LLM backbone and therefore tend to lose the original planning and reasoning abilities that these LLMs acquired through large-scale text pretraining.
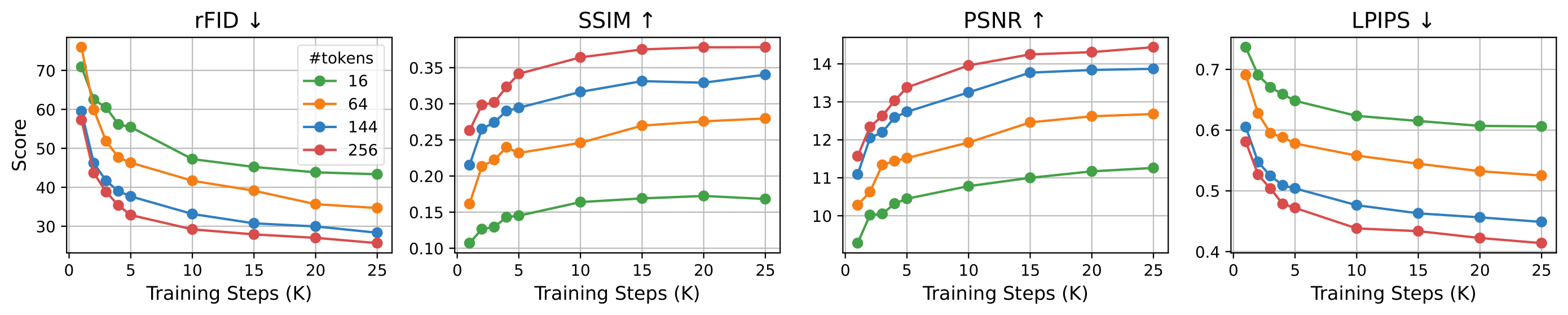

In Figure 2, we show that image reconstruction quality scales well with the number of patch-level CLIP latent tokens input to the Latent ControlNet. With only 1 epoch of training on the ImageNet dataset, images represented by 256 (=14x14) CLIP latent tokens not only achieve higher reconstruction accuracy, measured by rFID, SSIM, PSNR, and LPIPS, but also converge faster compared to those using fewer CLIP latent tokens. In Figure 3, we show qualitative examples of images generated with different numbers of CLIP latent tokens.

In Figure 4, we qualitatively compare the image reconstruction quality of our latent ControlNet with various unified models, including SEED, EMU, EMU2, GPT-4o, and MetaQuery. Specifically, we first encode the images using the visual encoder in Qwen2.5-VL, then use the latent ControlNet to reconstruct the images based solely on this visual information, without providing any text prompt as additional guidance. Trained exclusively on the ImageNet dataset for 3 epochs without exposure to any other open-world images, the reconstructions from Bifrost-1 latent ControlNet achieve quality that is competitive with or superior to strong baselines such as GPT-4o and MetaQuery, demonstrating the efficiency and robustness of our Latent ControlNet design.


Note that Bifrost-1 is designed as a bridging method that connects existing MLLMs with diffusion-based image generation models. As such, its performance, output quality, and potential visual artifacts are inherently influenced by the capabilities and limitations of the underlying backbone models it relies on. For instance, if the diffusion model used as the visual backbone struggles with generating complex, rare, or previously unseen scenes and objects, then Bifrost-1, which builds upon this foundation, may also exhibit suboptimal image generation results. This dependency highlights the importance of selecting strong and well-generalized base models when applying Bifrost-1 to real-world or open-domain generation tasks.
@misc{lin2025bifrost1bridgingmultimodalllms,
title={Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents},
author={Han Lin and Jaemin Cho and Amir Zadeh and Chuan Li and Mohit Bansal},
year={2025},
eprint={2508.05954},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.05954},
}